这个 project 主要是希望我们理解 MVCC 的一些相关知识。MVCC 的设计目标是通过维护多个版本的元组(tuple),使得不同的事务能够访问到与其时间戳一致的数据版本,而无需通过锁机制完全阻塞其他事务的操作。具体来说:
- 每个事务在启动时会被分配一个唯一的 事务 ID 或 读取时间戳 。
- 数据库系统会根据事务的读取时间戳,决定该事务能看到哪些数据版本:
- 可见性规则 :事务只能看到在其读取时间戳之前提交的数据版本。
- 不可见性规则 :事务不能看到在其读取时间戳之后提交或未提交的数据版本。
15445 的 lab 写了太久太久了,自己懒是一方面,实力不够也是一方面,task4 后面的 lab 就不打算写了(无奈.jpg)。在这整个过程中,学到的东西还挺多的,对于代码能力也有提升,以后有时间还是可以多看看配套的课程,然后再好好读读代码,写写注释和博客去深入理解理解,毕竟 bustub 的不论是代码架构还是规范我都觉得非常棒。后面就要像 15445 网页中写到的,去多关注生活中其他感兴趣的地方了,希望能够不断提升自己~
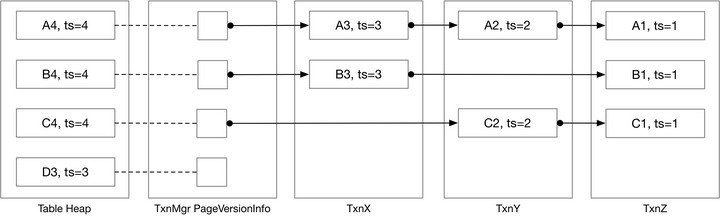
0. Bustub 中的 undolog
bustub 中在 TransactionManager 中通过一个哈希表来保存所有 tuple 的 undolog 起点:
| |
其中的 VersionUndoLink 也只是对 UndoLink 的一个包装:
| |
一个 tuple 最新的数据会保存在 table heap 中,而 txn manager 通过这个 tuple 的 rid 可以获取到这个 tuple 的 undolog:
exec_ctx_->GetTransactionManager()->GetUndoLink(rid);

1. Task 1 - Timestamps
每个事务有两个时间戳:
read_ts:事务开始时分配,表示该事务能看到的最新提交的数据版本。commit_ts:事务提交时分配,是一个单调递增的逻辑时间戳,决定事务的串行化顺序。
规则如下:
- 事务开始时(Begin),
read_ts = last_commit_ts - 事务提交时(Commit),
commit_ts = ++last_commit_ts
对于 Watermark 机制,其定义是所有活跃事务中的最小 read_ts,作用为确定哪些数据版本已经不再被任何事务读取,从而可以安全地清理旧版本数据。
这里很简单,就是需要在维护好系统中的 watermark,遍历事务映射中的所有事务,找出所有进行中事务中最小的 read_ts 为 watermark。在事务的 Begin、Commit、Abort 中需要使用 Watermark::AddTxn 和 Watermark::RemoveTxn 来更新 watermark。在更新时,可以使用红黑树或者哈希表 + 优先队列来快速找到最小的 read_ts。
2. Task2 - Storage Format and Sequential Scan
2.1 Tuple Reconstruction
数据库需要一种机制来“回溯”数据的历史版本,而 ReconstructTuple 正是这种机制的核心实现。
在 MVCC 系统中,表堆(table heap)通常存储的是最新的数据版本,而旧版本的元组信息则通过 undo logs 记录下来。当事务需要访问某个元组的历史版本时,ReconstructTuple 会从表堆中获取最新的元组,并根据 undo logs 逐步恢复出符合事务读取时间戳的版本。
在 MVCC 系统中,数据的删除操作并不会立即从表堆中移除元组,而是通过设置 is_deleted 标志来标记逻辑删除。ReconstructTuple 在处理 undo logs 时会检查 is_deleted 标志,从而判断某个元组是否已被删除。ReconstructTuple 将始终应用提供给函数的所有修改,而无需查看元数据或撤销日志中的时间戳。除了函数参数列表中提供的数据外,它不需要访问其他数据。
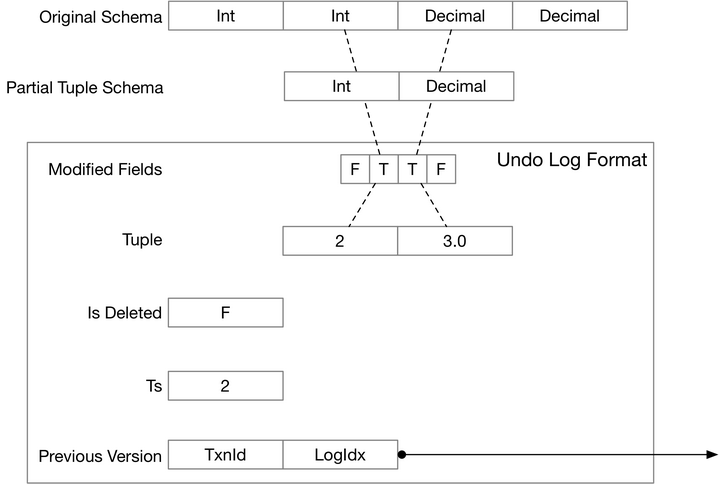
undo log 记录的是上次操作完的结果(换句话说,这次没操作前是什么样子),只有 modified_fields_ 是为了告诉这次操作,在上次修改完成之前 tuple 是什么样子。
modified_fields_:长度与 tuple 的 schema 相同,每个位代表在这次的操作中对于某个字段时候有更新tuple_:其长度 <= 原始的 tuple,只记录了 modified_fields_ 中为 true 的字段,并且保存的值是本次操作之前的值
ReconstructTuple 的工作流程:
- 从表堆中读取最新版本的元组(base_tuple)及其元数据(base_meta)。
- 初始化 tuple_values,存储元组的字段值。
- 获取最新元组
- 从表堆中读取最新版本的元组(base_tuple)及其元数据(base_meta)。
- 初始化 tuple_values,存储元组的字段值。
- 遍历 undo logs
- Undo logs 按时间戳降序排列,记录了元组的历史修改。
- 对于每个 undo log:
- 如果 is_deleted_ 为 true,标记元组为已删除。
- 否则,根据 modified_fields_ 更新 tuple_values 中对应字段的值。(所以这里类似于去覆盖更新)
- 生成结果元组
- 如果元组被标记为删除,返回空值。
- 否则,根据更新后的 tuple_values 构造并返回新的元组。
2.2 Sequential Scan / Tuple Retrieval
这里的意图就是需要在 bustub 执行 seq executor 算子时找到当前事务可以使用的 tuple。
判断当前 tuple 是否对当前事务可见:
- case1:tuple 的 ts_ 比 txn_read_ts 小,则 tuple 对当前事务可见
- case2:tuple 的 ts_ 等于 txn_temp_ts,则 tuple 对当前事务可见
- case3:不满足 case1 也不满足 case2,则 tuple 对当前事务不可见
如果是 case1 和 case2,说明当前事务可以直接使用 table heap 中的这条 tuple;而如果是 case3,则需要遍历这条 tuple 的版本链,找出可以用的 undolog,如果有就使用 ReconstructTuple 来重建一个可见的历史版本的 tuple。
3. Task3 - MVCC Executors
在插入一条记录时,要把这条记录的主键值记下来,这样之后回滚时只需要把这个主键值对应的记录删掉就好了; 在删除一条记录时,要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入到表中就好了; 在更新一条记录时,要把被更新的列的旧值记下来,这样之后回滚时再把这些列更新为旧值就好了。 from 小林coding - 为什么需要-undo-log
简单理解:改了什么,你就保存什么。
Insert
在这一步只需要将插入的 tuple 的 rid 记录到事务 write set 中,然后在 txn manager 中设置新 tuple 的 undolog 链为空(相当于给这个 undolog 链初始化)。
为什么 Insert 操作不需要 undo log
在 MVCC(多版本并发控制)机制下,每个事务看到的数据版本取决于其时间戳。对于 INSERT 操作,由于插入的是全新的记录,不存在“历史版本”的问题。因此,不需要为 INSERT 操作维护 Undo Log 来支持 MVCC 中的版本链。
当执行一个 INSERT 操作时,如果事务需要回滚,只需删除刚刚插入的记录即可,而无需像 UPDATE 或 DELETE 那样恢复旧数据状态。因此,INSERT 操作只需要记录被插入记录的主键信息,以便在回滚时定位并删除该记录。这种情况下,Undo Log 的作用非常有限,甚至可以省略。
相比之下,UPDATE 和 DELETE 操作会创建新的版本或标记旧版本为无效,这些都需要通过 Undo Log 来记录和管理。
Update & Delete
在修改操作(update 和 delete)中,对于 tuple 中的字段有两种情况:
- 情况 1(当前事务在未提交前进行了修改):由于每个事务都对当前操作的 tuple 的 undolog 只能保存一份,因此在生成本次的 undolog 后还需要需要合并上一次的 undolog。
- 情况 2(这是当前事务第一次修改):创建一个新的 undolog,并把它添加到版本链中。
在完成修改操作后,需要更新 table heap 中的值:修改 tuple 的数据为更新后的值,同时更新 tuple 的 meta,其时间戳为当前事务的 temp ts(这可用于标识这个 tuple 正在被哪个事务修改);然后还要将当前修改 tuple 的 id(也就是其 rid)添加到当前事务的 write set,这在事务提交时会根据 rid 来正确设置 table heap 中 tuple 的 ts。
Commit
刚刚说到在修改时需要修改 tuple 的 meta 数据中的 ts 为当前事务的 temp ts,因为此时事务还没提交,使用 temp ts 就能分辨出现在这条 tuple 是否正在被修改:temp ts 是一个很大的数(TXN_START_ID + txn_id,其中 TXN_START_ID = 1LL << 62),事务的 read ts 和 commit ts 都会小于这个数;在判断一个 tuple 是否可见时,都是通过事务的 read ts(txn.read_ts)与 tuple.meta.ts 进行比较,如果 tuple.meta.ts <= txn.read_ts,那么这个 tuple 对于 txn 是可见的,而如果 tuple.meta.ts == txn.temp_ts,则这个 tuple 正在被 txn 进行修改。
这样的话,即便是在修改后 tuple.meta.ts 也只是事务的 temp ts,所以在 commit 时,需要将其设置为系统的最新 commit ts。这里需要做几点:
- 获取当前系统的 commit ts,计算方式为
last_commit_ts_ + 1 - 遍历当前要提交的事务的 write set,更新修改了的 tuple 的 meta 数据,将 meta.ts 设置为 commit ts
- 设置事务的 commit ts,并且更新系统的 last_commit_ts
GarbageCollection
之前一旦我们将事务添加到 txn manager 中,我们就永远不会删除它,因为 read_ts 较小的事务可能需要读取存储在先前已提交或已中止事务中的撤销日志。这里需要实现 TransactionManager::GarbageCollection() 函数,删除未使用的事务。
一个事务在运行时只需要看到它自己的快照,一旦事务结束,它所依赖的数据版本就可以被考虑回收。只有当某个数据版本不再被任何活跃事务需要时,才能进行垃圾回收(GC)。
举个🌰,假设我们有如下记录:
| RID | ts_ | 数据 |
|---|---|---|
| A | 1 | Alice |
| A | 2 | Bob |
| A | 3 | Charlie |
| A | 4 | David |
这表示记录 A 被不同事务更新了四次。现在系统中有三个事务:
| 事务 ID | 状态 | 可见性范围 |
|---|---|---|
| T2 | RUNNING | ts ≤ 2 |
| T4 | RUNNING | ts ≤ 4 |
| T5 | RUNNING | ts ≤ 5 |
watermark = 2(最小活跃事务 ID)
Q1: T5 能看到 ts_=1 的数据吗?
没问题,因为 T5 的 ts=5 > 1,且事务 1 已完成。
Q2: ts_=1 的数据可以被清理吗?
不可以,因为 T2(ts=2)还在运行,它的可见范围是 ts ≤ 2,所以它可能会访问 ts=1 的数据。
Q3: 如果 T2 提交或中止,watermark 会变成多少?此时 ts=1 的数据能被清理吗?
- watermark 更新为 min(4,5) = 4
- 此时所有活跃事务的 ts ≥ 4
- 所以 ts ≤ 3 的数据都对活跃事务不可见 → 可以安全清理
这里有一个关键点:可见 ≠ 不可清理
- 可见性:表示某个事务是否能看到某条记录(比如 T5 能看到 ts_=3 的记录)
- 清理条件:表示这条记录是否仍然被任何一个活跃事务所需要,如果没有任何活跃事务再访问它,就可以清理
所以 GC 的步骤可以简单总结如下:
- 遍历数据库中所有 tuple
- 判断 tuple.ts_ ≤ watermark → 不再被活跃事务访问
- 沿着 undo link 遍历 undo log 链
- 统计每个事务有多少 undo log 不再被访问
- 如果某个事务所有 undo log 都不可见,且事务已完成 → 删除其 undo log 和事务元信息