引言
在性能分析和系统调优中,了解应用程序在运行时的调用栈信息至关重要。在 【eBPF 入门实践教程十二:使用 eBPF 程序 profile 进行性能分析】 这篇文章中,其利用 Rust + eBPF 构建了一个 profiler 工具,抱着学习的目的,我使用 C++ 实现了相同的功能,并将所学知识总结成本文。
perf_event_open 机制解析
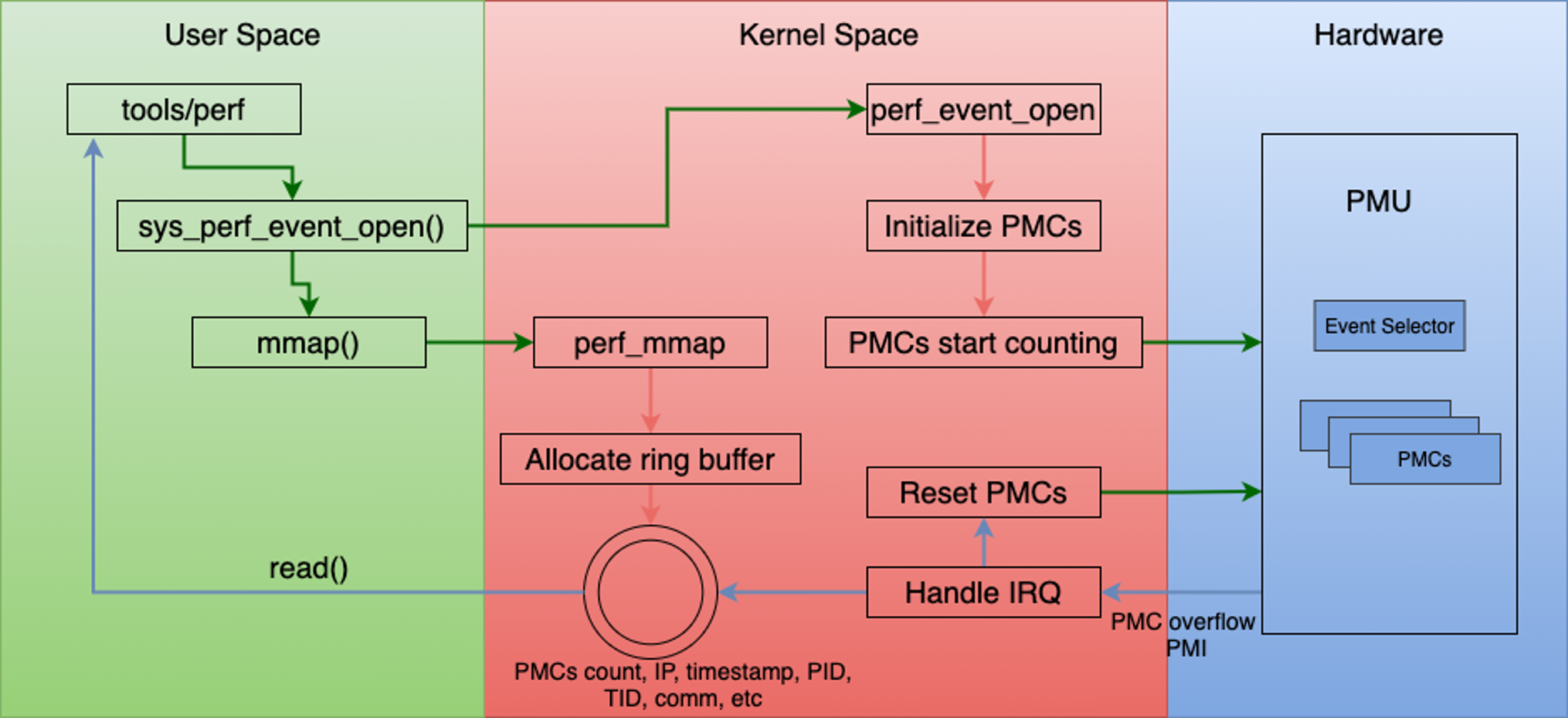
perf 原理图:https://plantegg.github.io/2021/05/16/Perf_IPC%E4%BB%A5%E5%8F%8ACPU%E5%88%A9%E7%94%A8%E7%8E%87/
perf_event_open 是 Linux 内核提供的性能监控接口,允许用户空间程序创建性能事件计数器。当用户态程序调用 sys_perf_event_open 系统调用时,内核会创建相应的性能监控实例。以下是基本的使用方式:
1
2
3
4
5
6
7
8
| #include <linux/perf_event.h>
#include <sys/syscall.h>
#include <unistd.h>
int64_t perf_event_open(struct perf_event_attr* hw_event, pid_t pid, int cpu,
int group_fd, unsigned long flags) {
return syscall(SYS_perf_event_open, hw_event, pid, cpu, group_fd, flags);
}
|
以文件描述符为中心的监控单元
Linux 遵循 " 一切皆文件 " 的设计哲学,perf_event_open 也不例外。每次调用该函数,内核都会创建一个独立的性能监控实例,并返回一个文件描述符。
核心概念:
- 1 fd = 1 Event:每个文件描述符对应一个具体的监控任务,例如 " 监控 CPU 0 的指令执行数 "
- 事件分组 (Group):多个文件描述符可以绑定在一起形成事件组
分组的重要性:
假设需要计算 " 每条指令的缓存未命中率 “,需要同时监控 " 指令数 " 和 " 缓存未命中数 “。将它们放入同一事件组可以确保:
- 两个事件同时开始、同时结束计数
- 硬件计数器同步采样,保证计算比例的准确性
- 减少系统调用开销
事件状态控制:ioctl 与 prctl
创建事件后,可以通过以下方式控制其运行状态:
- ioctl (Input/Output Control):针对单个文件描述符的操作
ioctl(fd, PERF_EVENT_IOC_ENABLE):启用事件监控ioctl(fd, PERF_EVENT_IOC_DISABLE):暂停事件监控
- prctl (Process Control):针对当前进程所有事件的批量操作
- 适用于管理多个监控事件的场景,避免频繁的
ioctl 调用
设计优势:事件被禁用时,计数器暂停但数据保留。这种设计允许在程序特定阶段(如关键算法执行期间)精确开启监控,实现细粒度的性能分析。
两种工作模式:计数 vs 采样
perf_event 支持两种基本工作模式,满足不同的性能分析需求:
计数模式 (Counting Mode)
内核维护一个简单的计数器(通常是 u64 类型整数)。计数事件的结果通过 read 系统调用收集。
特点:
- 低开销:仅维护计数器,不记录详细上下文
- 结果简单:返回事件发生的总次数
- 应用场景:基准测试、性能统计
- 例如:” 这段代码执行消耗了多少 CPU 周期 "
- " 函数调用发生了多少次缓存未命中 "
采样模式 (Sampling Mode)
设置采样阈值(如每 1000 次缓存未命中采样一次)。当事件计数器溢出时,内核会捕获当前的执行上下文(包括指令指针、进程 ID、调用栈等)。
工作原理:
- 内核分配环形缓冲区用于存储采样数据
- 采样数据通过内存映射 (
mmap) 暴露给用户空间 - 用户程序从缓冲区 " 消费 " 采样数据
优势:
- 记录详细的执行上下文信息
- 支持调用栈回溯
- 应用场景:性能热点分析、火焰图生成、函数调用频率统计
结合 eBPF 实现 profiling
传统 perf 工具虽然功能强大,但在某些场景下存在局限性。eBPF 提供了更灵活、更低开销的性能监控方案。通过将 eBPF 程序挂载到 perf_event 上,我们可以在内核空间直接处理性能事件,实现高效的调用栈采集。
核心思路:
- 利用
perf_event 触发采样事件 - eBPF 程序在内核中捕获事件并采集调用栈信息
- 通过 Ring Buffer 高效传输数据到用户空间
- 用户空间程序解析并展示结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| #include "vmlinux.h"
#include <bpf/bpf_helpers.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
#ifndef TASK_COMM_LEN
#define TASK_COMM_LEN 16
#endif
#ifndef MAX_STACK_DEPTH
#define MAX_STACK_DEPTH 128
#endif
typedef __u64 stack_trace_t[MAX_STACK_DEPTH];
struct stack_trace_event {
__u32 pid;
__u32 cpu_id;
__u64 timestamp;
char comm[TASK_COMM_LEN];
__s32 kstack_sz;
__s32 ustack_sz;
stack_trace_t kstack;
stack_trace_t ustack;
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 256 * 1024);
} events SEC(".maps");
SEC("perf_event")
int profile(void* ctx) {
struct stack_trace_event* event =
bpf_ringbuf_reserve(&events, sizeof(struct stack_trace_event), 0);
if (!event) {
return 1;
}
int pid = bpf_get_current_pid_tgid() >> 32;
int cpu_id = bpf_get_smp_processor_id();
event->pid = pid;
event->cpu_id = cpu_id;
event->timestamp = bpf_ktime_get_ns();
// 获取当前进程名
if (bpf_get_current_comm(event->comm, sizeof(event->comm))) {
event->comm[0] = 0;
}
// 获取内核栈、用户栈信息
event->kstack_sz =
bpf_get_stack(ctx, event->kstack, sizeof(event->kstack), 0);
event->ustack_sz = bpf_get_stack(
ctx, event->ustack, sizeof(event->ustack), BPF_F_USER_STACK);
bpf_ringbuf_submit(event, 0);
return 0;
}
|
eBPF 程序执行流程:
- 程序挂载到
perf_event,随性能计数器(CPU 周期、指令数等)或定时器触发 - 每次触发时,eBPF 程序在内核空间执行一次
- 采集关键性能数据并通过 Ring Buffer 传输到用户空间
采集的关键信息:
- 进程标识:当前运行进程的 PID
- CPU 信息:执行任务的 CPU 核心编号
- 时间戳:事件发生的精确时间(纳秒级)
- 进程名:可执行文件名称
- 栈回溯:内核栈和用户栈的完整调用链
数据结构设计:
1
2
3
4
5
6
7
8
9
10
| struct stack_trace_event {
__u32 pid; // 进程 ID
__u32 cpu_id; // CPU 核心编号
__u64 timestamp; // 时间戳(纳秒)
char comm[TASK_COMM_LEN]; // 进程名
__s32 kstack_sz; // 内核栈大小
__s32 ustack_sz; // 用户栈大小
stack_trace_t kstack; // 内核栈地址数组
stack_trace_t ustack; // 用户栈地址数组
};
|
应用价值:
采集的数据经过处理后,可以生成 火焰图 (Flame Graphs),直观展示:
- CPU 消耗分布:哪个进程/函数占用最多 CPU 时间
- 调用链分析:热点函数的完整调用路径
- 内核/用户态比例:系统调用与业务逻辑的时间分配
- 性能瓶颈定位:快速识别性能热点和优化机会
解析采集的栈回溯信息
API 设计
定义内核返回的 event 结构体:
1
2
3
4
5
6
7
8
9
10
| struct StacktraceEvent {
uint32_t pid;
uint32_t cpu_id;
uint64_t timestamp;
char comm[TASK_COMM_LEN];
int32_t kstack_size;
int32_t ustack_size;
uint64_t kstack[MAX_STACK_DEPTH];
uint64_t ustack[MAX_STACK_DEPTH];
};
|
定义事件处理器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| enum class OutputFormat : uint8_t { Standard, FoldExtend };
class EventHandler {
public:
EventHandler(OutputFormat fmt) : format(fmt) {
boot_time_ns = get_boot_time_ns();
}
~EventHandler() = default;
auto handle(const uint8_t* data, size_t len) -> int;
void show_stack_trace(const uint64_t* stack, uint32_t size, uint32_t pid);
private:
blaze::Symbolizer symbolizer_;
OutputFormat format;
uint64_t boot_time_ns;
static auto get_boot_time_ns() -> uint64_t;
// 符号化堆栈并返回字符串向量
auto symbolize_stack_to_vec(const uint64_t* stack, uint32_t stack_sz,
uint32_t pid) -> std::vector<std::string>;
void handle_standard(const StacktraceEvent* event);
void handle_fold_extend(const StacktraceEvent* event);
};
|
符号化解析:将地址转换为函数名
eBPF 采集的调用栈信息是内存地址数组,需要转换为可读的函数名和源代码位置。这里使用 blazesym 库进行符号化解析,并封装为易用的 C++ 接口。
符号化的重要性:
- 原始地址(如
0xffffffff81000000)对人类不友好 - 需要转换为函数名(如
do_syscall_64)和源代码位置 - 支持内核符号和用户空间符号的差异化处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
| #ifndef BLAZE_H_
#define BLAZE_H_
#include <cstdint>
#include <format>
#include <variant>
#include <blazesym.h>
#include "utils.h"
namespace blaze {
struct CodeInfo {
const blaze_symbolize_code_info* info_;
CodeInfo(const blaze_symbolize_code_info* info) : info_(info) {}
};
struct Syms {
const blaze_syms* syms_;
Syms(const blaze_syms* syms) : syms_(syms) {}
~Syms() {
if (syms_) {
blaze_syms_free(syms_);
}
}
// 禁止拷贝,防止双重释放
Syms(const Syms&) = delete;
auto operator=(const Syms&) -> Syms& = delete;
};
// 符号源
using Source =
std::variant<blaze_symbolize_src_process, blaze_symbolize_src_kernel>;
struct Input {
const uint64_t* addrs_;
size_t cnt_;
};
struct Symbolizer {
blaze_symbolizer* symbolizer_;
Symbolizer() { symbolizer_ = blaze_symbolizer_new(); }
~Symbolizer() { blaze_symbolizer_free(symbolizer_); }
[[nodiscard]]
auto symbolize(Source src, const Input& input) const -> Result<Syms> {
if (!input.addrs_ || input.cnt_ == 0) {
return Err<>{"Empty input addresses"};
}
const blaze_syms* syms = nullptr;
std::visit(
Overloaded{
[&](blaze_symbolize_src_kernel& kern_src) -> void {
syms = blaze_symbolize_kernel_abs_addrs(
symbolizer_, &kern_src, input.addrs_, input.cnt_);
},
[&](blaze_symbolize_src_process& proc_src) -> void {
syms = blaze_symbolize_process_abs_addrs(
symbolizer_, &proc_src, input.addrs_, input.cnt_);
},
},
src);
return syms
? Result<Syms>{syms}
: Err<>{std::format("Symbolization failed, errno is: {}",
static_cast<int16_t>(blaze_err_last()))};
}
};
inline auto get_symbolize_source(uint32_t pid) -> blaze::Source {
if (pid == 0) {
blaze_symbolize_src_kernel src{
.type_size = sizeof(src),
};
return blaze::Source{src};
} else {
blaze_symbolize_src_process src{
.type_size = sizeof(src),
.pid = pid,
};
return blaze::Source{src};
}
}
} // namespace blaze
#endif /* BLAZE_H_ */
|
其中的 Result、Err、Overloaded 分别借鉴了 Rust 中的 Result、Err 和 match。
Symbolizer::symbolize 用于把绝对地址数组符号化(转成符号/调试信息):
- 如果
input.addrs_ 为 null 或 input.cnt_ == 0,返回错误 Err<>{"Empty input addresses"}。 - 根据参数
src(Source 是 blaze_symbolize_src_process 或 blaze_symbolize_src_kernel 的 std::variant)调用不同的符号化接口:- 内核源时调用
blaze_symbolize_kernel_abs_addrs(symbolizer_, &kern_src, input.addrs_, input.cnt_); - 进程源时调用
blaze_symbolize_process_abs_addrs(symbolizer_, &proc_src, input.addrs_, input.cnt_)。
使用 std::visit + Overloaded 选择分支。
- 结果处理:把返回的
const blaze_syms* syms 封装进 Syms(RAII,析构时会调用 blaze_syms_free)。若 syms 非空则返回 Result<Syms>{syms};否则返回带有 blaze_err_last()(转换为整数)的错误信息。
事件处理
EventHandler::handle 接收的是一块“原始二进制缓冲区”(raw bytes)而不是已经解析好的结构体,所以用 const uint8_t* data, size_t len 更通用、安全,并且允许在用户态从 ring/payload、socket 或 perf buffer 等来源直接读取数据并检查长度后再解析(在这个项目中,数据从 ringbuf 中获取)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| auto EventHandler::handle(const uint8_t* data, size_t len) -> int {
if (len != sizeof(StacktraceEvent)) {
std::println("Data length mismatch: expected {}, got {}",
sizeof(StacktraceEvent),
len);
return 1;
}
const auto* const event = reinterpret_cast<const StacktraceEvent*>(data);
if (event->kstack_size <= 0 && event->ustack_size <= 0) {
return 1;
}
if (format == OutputFormat::Standard) {
handle_standard(event);
} else {
handle_fold_extend(event);
}
return 0;
}
|
标准输出格式:可读的逐帧展示
handle_standard 方法生成人类可读的调用栈输出,包含完整的时间戳、进程信息和源代码位置。这种格式适合直接查看和分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
| static void print_frame(const char* name, Option<AddrInfo> addr_info,
const blaze_symbolize_code_info* code_info) {
std::string code_str;
if (code_info != nullptr) {
// path
if ((code_info->dir != nullptr) && (code_info->file != nullptr)) {
code_str = std::format(" {}/{})", code_info->dir, code_info->file);
} else if (code_info->file != nullptr) {
code_str = code_info->file;
}
// line and column
if (code_info->line > 0) {
code_str += std::format(":{}", code_info->line);
if (code_info->column > 0) {
code_str += std::format(":{}", code_info->column);
}
}
}
if (addr_info.has_value()) {
auto [input_addr, addr, offset] = *addr_info;
std::println("0x{:0>{}}: {} @ {:#x} + {:#x}{}",
input_addr,
ADDR_WIDTH,
(name != nullptr) ? name : "<unknown>",
addr,
offset,
code_str);
} else {
std::println("{:>{}} {}{} [inlined]", "", ADDR_WIDTH, name, code_str);
}
}
void EventHandler::show_stack_trace(const uint64_t* stack, uint32_t size,
uint32_t pid) {
blaze::Source src = blaze::get_symbolize_source(pid);
size_t count = static_cast<size_t>(size) / sizeof(uint64_t); // 栈帧数量
auto result = symbolizer_.symbolize(
src, blaze::Input{.addrs_ = stack, .cnt_ = count});
if (!result) {
std::println(stderr,
" Failed to symbolize stack trace. err: {}",
result.error());
return;
}
const auto* syms = result->syms_;
for (size_t i = 0; i < count; ++i) {
if (i < syms->cnt && (syms->syms[i].name != nullptr)) {
print_frame(
syms->syms[i].name,
Option<AddrInfo>(std::make_tuple(
stack[i], syms->syms[i].addr, syms->syms[i].offset)),
&syms->syms[i].code_info);
// 打印内联函数信息
for (size_t j = 0; j < syms->syms[i].inlined_cnt; ++j) {
print_frame(syms->syms[i].inlined[j].name,
std::nullopt,
&syms->syms[i].inlined[j].code_info);
}
} else {
std::println("{:>0{}}: <no-symbol>", stack[i], ADDR_WIDTH);
}
}
}
void EventHandler::handle_standard(const StacktraceEvent* event) {
uint64_t unix_ns = event->timestamp + boot_time_ns;
std::println("[{}.{:09} COMM: {} (pid={}) @ CPU {}]",
unix_ns / 1'000'000'000,
unix_ns % 1'000'000'000,
event->comm,
event->pid,
event->cpu_id);
// 打印内核栈
if (event->kstack_size > 0) {
std::println("Kernel:");
show_stack_trace(event->kstack, event->kstack_size, 0);
} else {
std::println("Kernel: <no stack>");
}
// 打印用户栈
if (event->ustack_size > 0) {
std::println("Userspace:");
show_stack_trace(event->ustack, event->ustack_size, event->pid);
} else {
std::println("Userspace: <no stack>");
}
std::println();
}
|
火焰图格式:机器可读的数据输出
handle_fold_extend 生成折叠行(comm-pid;frame;... 1),用于生成火焰图(FlameGraph)。handle_fold_extend 对每个栈结果做 reverse,把栈从“根”(程序入口)到“叶”(当前帧)排列,符合火焰图期望的父到子顺序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| auto EventHandler::symbolize_stack_to_vec(const uint64_t* stack,
uint32_t stack_sz, uint32_t pid)
-> std::vector<std::string> {
if (stack_sz <= 0) {
return {};
}
blaze::Source src = blaze::get_symbolize_source(pid);
size_t count = stack_sz / sizeof(uint64_t);
auto result = symbolizer_.symbolize(
src, blaze::Input{.addrs_ = stack, .cnt_ = count});
if (!result) {
return {};
}
const auto* syms = result->syms_;
std::vector<std::string> vec;
if (syms == nullptr) {
for (size_t i = 0; i < count; ++i) {
vec.push_back(std::format("0x{:x}", stack[i]));
}
return vec;
}
for (size_t i = 0; i < syms->cnt; ++i) {
if (syms->syms[i].name != nullptr) {
vec.emplace_back(syms->syms[i].name);
} else {
vec.push_back(std::format("0x{:x}", stack[i]));
}
}
return vec;
}
void EventHandler::handle_fold_extend(const StacktraceEvent* event) {
std::vector<std::string> stack_frames;
// 为了让火焰图能够按进程聚合,将 "comm-pid" 作为栈底
stack_frames.push_back(std::format("{}-{}", event->comm, event->pid));
// 处理用户态
if (event->ustack_size > 0) {
auto user_frames = symbolize_stack_to_vec(
event->ustack, event->ustack_size, event->pid);
for (const auto& frame : user_frames | std::views::reverse) {
stack_frames.push_back(frame);
}
}
// 处理内核态
if (event->kstack_size > 0) {
auto kern_frames =
symbolize_stack_to_vec(event->kstack, event->kstack_size, 0);
for (const auto& frame : kern_frames | std::views::reverse) {
stack_frames.push_back(frame + "_[k]");
}
}
auto temp = stack_frames | std::views::join_with(';');
// 输出格式:stack;frames 1
// FlameGraph 工具期望每行以空格和数字结尾
std::println("{} 1", temp | std::ranges::to<std::string>());
}
|
流程图
flowchart TD
A[eBPF 程序(内核)
采集 stacktrace
] --> B[Userspace reader
接收 StacktraceEvent]
B --> C[EventHandler::handle
校验 & 选择输出格式]
C --> D{有 ustack?}
C --> E{有 kstack?}
D -- yes --> U1["构造 blaze::Source (process)
构造 blaze::Input(addrs,cnt)"]
E -- yes --> K1["构造 blaze::Source (kernel)
构造 blaze::Input(addrs,cnt)"]
U1 --> S1["Symbolizer::symbolize
(std::visit -> process API)"]
K1 --> S2["Symbolizer::symbolize
(std::visit -> kernel API)"]
S1 --> F{symbolize 成功?}
S2 --> F
F -- yes --> G[返回 Syms(RAII)]
F -- no --> H["返回 Err
记录 blaze_err_last() -> fallback: 打印原始地址"]
G --> P1[show_stack_trace
逐帧打印(含内联)]
G --> P2[symbolize_stack_to_vec
生成折叠帧向量]
P2 --> M[组装折叠行 -> 输出给 FlameGraph]
P1 --> O[标准可读输出]
H --> O2[打印原始地址 / 记录错误日志]
style U1 fill:#e6ffed,stroke:#2d9a3b
style K1 fill:#e6f0ff,stroke:#2176d2
style H fill:#fff1f0,stroke:#d9534f启动与事件循环
这一节描述用户态程序如何完成启动准备并进入事件轮询:解析命令行与日志级别、提升必要的资源限制、加载并 attach eBPF 程序、通过 ring buffer 接收内核事件、调用 EventHandler 进行解析输出,以及在接收到信号时优雅退出。
关键依赖与权限
依赖项:libbpf(加载 BPF 对象与 maps)、spdlog(日志)、CLI11(命令行解析)、可选的内核 BTF / vmlinux(用于内核符号化)。
运行权限:通常需要 root 或至少 CAP_BPF/CAP_SYS_ADMIN。另外必须提升 RLIMIT_MEMLOCK,否则内核会因为无法锁定内存而拒绝加载 BPF 对象。
建议在启动前做最基本的环境检查:
1
2
| uname -r
which bpftool
|
命令行与日志初始化
使用 CLI11 解析采样频率(-f)、PID 过滤(-p)、输出格式(-E)等选项,并使用 spdlog 配置默认日志器与日志等级。示例代码:
1
2
3
4
5
6
7
8
9
10
11
| CLI::App app{"A simple profiler using eBPF"};
Args args;
app.add_option("-f,--freq", args.freq, "Sampling frequency")->default_val(10);
app.add_flag("-E,--fold-extend", args.fold_extend, "Output in extended folded format");
CLI11_PARSE(app, argc, argv);
using Level = spdlog::level::level_enum;
Level level = (args.verbosity == 0) ? Level::warn : (args.verbosity==1 ? Level::info : Level::debug);
auto console = spdlog::stdout_color_mt("console");
spdlog::set_default_logger(console);
spdlog::set_level(level);
|
将日志级别与命令行绑定,便于在调试时查看详细符号化错误或在生产时降低输出噪音。
提升资源限制(RLIMIT_MEMLOCK)
BPF 对象和 ring buffer 需要被内核锁定在内存。推荐将 RLIMIT_MEMLOCK 设为无限以避免加载失败:
1
2
| rlimit rl = {.rlim_cur = RLIM_INFINITY, .rlim_max = RLIM_INFINITY};
setrlimit(RLIMIT_MEMLOCK, &rl);
|
在受限环境下(容器、受限用户)应提前确认是否允许修改该限制。
加载并管理 BPF 对象(ProfilerSkel)
通过 bpf 的 skeleton(例如 profiler_bpf)生成的封装,使用 RAII 管理生命周期:open/load 在构造时完成,资源在析构时释放。若加载失败,应立即记录错误并退出。
1
2
3
4
5
6
7
8
9
| struct ProfilerSkel {
profiler_bpf* obj{nullptr};
ProfilerSkel() { obj = profiler_bpf::open_and_load(); if (obj == nullptr) spdlog::error("Failed to open and load BPF object"); }
~ProfilerSkel() { if (obj) profiler_bpf__destroy(obj); }
operator bool() const { return obj != nullptr; }
auto operator->() const -> profiler_bpf* { return obj; }
};
|
在加载成功后,还可能需要对 map 进行预初始化(例如设置 PID 过滤器)或为 symbolization 提供 vmlinux 路径。
初始化 perf 事件并 attach
根据配置(采样频率、是否使用软件事件、是否按 PID 过滤等)创建 perf event 文件描述符并返回给调用方;随后将这些 fd attach 到 eBPF 程序的 entry(例如 profile)上。初始化失败时应当记录并退出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| // perf.cpp
auto init_perf_monitor(uint64_t freq, bool sw_event, pid_t pid = -1)
-> Result<std::vector<int>, libbpf_errno> {
int cpus = libbpf_num_possible_cpus();
if (cpus < 0) {
return Err(libbpf_errno::LIBBPF_ERRNO__INTERNAL);
}
perf_event_attr attr = {
.type = sw_event ? PERF_TYPE_SOFTWARE : PERF_TYPE_HARDWARE, // 采样类型
.size = sizeof(perf_event_attr),
.config = (sw_event ? static_cast<uint64_t>(PERF_COUNT_SW_CPU_CLOCK)
: static_cast<uint64_t>(PERF_COUNT_HW_CPU_CYCLES)),
.sample_freq = freq, // 设置频率,每秒 freq 次采样
.freq = 1, // 标志位:设为 1 表示使用 sample_freq
};
std::vector<int> fds;
for (int cpu = 0; cpu < cpus; ++cpu) {
int fd = static_cast<int>(perf_event_open(&attr, pid, cpu, -1, 0));
if (fd < 0) {
return Err(libbpf_errno::LIBBPF_ERRNO__INTERNAL);
}
fds.push_back(fd);
}
return fds;
}
auto attach_perf_events(const std::vector<int>& fds, bpf_program* prog)
-> std::vector<Result<bpf_link*, libbpf_errno>> {
std::vector<Result<bpf_link*, libbpf_errno>> links;
for (int fd : fds) {
auto* link = bpf_program__attach_perf_event(prog, fd);
if (libbpf_get_error(link) != 0) {
links.emplace_back(Err(libbpf_errno::LIBBPF_ERRNO__INTERNAL));
}
links.emplace_back(link);
}
return links;
}
// ---------------------------------------------------------------
// main.cpp
auto perf_fds = init_perf_monitor(freq, args.sw_event, args.pid);
if (!perf_fds) {
spdlog::error("Failed to initialize perf monitor");
return 1;
}
attach_perf_events(perf_fds.value(), obj->progs.profile);
|
attach 成功后,内核采样事件触发时会进入 eBPF 程序,程序会把数据写入之前声明的 ring buffer map。
Ring Buffer 与事件回调
用户态通过 ring buffer 从内核读取事件样本。回调函数负责类型安全地把原始字节传递给 EventHandler::handle,由其完成长度检查、解析与输出。
1
2
3
4
5
6
7
8
9
10
| static auto handle_event_wrapper(void* ctx, void* data, size_t data_sz) -> int {
auto* handler = static_cast<EventHandler*>(ctx);
return handler->handle(static_cast<const uint8_t*>(data), data_sz);
}
RingBuffer rb{bpf_map__fd(obj->maps.events), handle_event_wrapper, &event_handler, nullptr};
if (!rb) {
spdlog::error("Failed to create ring buffer");
return 1;
}
|
要点:
- 回调签名使用
const uint8_t* data, size_t data_sz,有利于在用户态对来自不同来源(ringbuf、perf buffer、socket 等)的原始字节流做统一处理和边界校验; - ring buffer 的容量应根据采样频率与处理速率调整,避免丢失样本。
主循环、轮询与优雅退出
主循环负责轮询 ring buffer,并在接收到中断信号时优雅退出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| static volatile bool exiting = false;
static void sig_handler(int sig) { exiting = true; }
...
signal(SIGINT, sig_handler);
while (!exiting) {
int err = rb.poll(100);
if (err == -EINTR) {
// Interrupted by signal, continue to check exiting flag
continue;
}
if (err < 0) {
spdlog::error("Error polling ring buffer: {}", err);
break;
}
}
auto r = close_perf_events(perf_fds.value());
if (!r) {
spdlog::error("Failed to close perf events, error message is: {}",
static_cast<int>(r.error()));
return 1;
}
|
退出流程要点:
- signal handler 仅设置原子/易变标志,实际清理在主线程完成;
- 调用
close_perf_events 关闭 perf fds,确保內核计数器停止并释放资源; - 依赖 RAII 的 BPF skeleton 在作用域结束时销毁 BPF 对象和 maps。
这样可以保证在收到 SIGINT / SIGTERM 时,程序能够尽量把已经到达的样本处理完并正确释放所有内核资源。
对 eBPF 程序挂载方式的思考
在使用 libbpf 开发 BPF 程序时,通常 skeleton 会提供的自动 attach 机制 bpf_object__attach_skeleton,但在实际实现 perf 采样监控(例如 init_perf_monitor 这类逻辑)的过程中,最终选择的是手动创建 perf_event fd,并使用 bpf_program__attach_perf_event 进行挂载。这并不是因为 skeleton 不好,而是两者适用的层级和场景并不相同。
skeleton attach 是什么,它解决了什么问题?
skeleton attach(本质是 bpf_object__attach_skeleton 或生成代码中的 xxx__attach())是一种高层抽象:
- 在 BPF ELF 中通过 section 描述程序的 attach 类型
- libbpf 根据这些元信息,自动把所有 program 挂载到对应的 hook 点
- 用户态几乎不需要关心 attach 的细节
它非常适合下面这些场景:
- attach 类型是 静态的、编译期就确定的
- 比如 tracepoint、kprobe、raw_tp 等
- 希望快速把程序跑起来,而不是写大量样板代码
在这些情况下,skeleton attach 是几乎没有理由拒绝的。但当 attach 对象变成 perf event 时,情况就不太一样了。
perf 场景下的不同
perf 事件并不是一个“天然存在的 hook 点”,而是需要用户态显式创建的:
- 需要调用
perf_event_open - 需要构造
perf_event_attr - 需要决定:
- 是按 CPU 还是按 PID
- 采样频率 / period
- 是否 per-CPU 创建多个 fd
这些信息天然属于运行时配置,而不是 ELF 元信息的一部分。
而 skeleton attach 的设计假设是:
attach 行为已经在 BPF 程序中声明好,用户态只负责“一次性挂上去”。
因而这里选择了另一条路径:
- 在用户态显式创建 perf_event fd
- 将单个
bpf_program 附加到指定的 perf fd 上
也就是使用:
1
| bpf_program__attach_perf_event(prog, perf_fd);
|
这种方式带来的好处,主要体现在控制权完全回到用户态。
program attach 挂载的好处
(1)attach 粒度更细
- skeleton attach:
- 以整个 skeleton 为单位
- 自动 attach 多个 program / link
- program attach:
- 明确地控制“哪个 program → 哪个 perf fd”
这在 perf 场景下非常重要,因为 fd 本身就是策略的一部分。
(2)perf 参数可以在运行时自由配置
通过手动创建 perf fd,可以在用户态精确控制:
- 采样频率(freq / period)
- perf event 类型
- 绑定到哪个 CPU 或 PID
- 是否为每个 CPU 创建独立 fd
这些配置很难优雅地放进 skeleton 的自动 attach 流程中,但却是 perf 采样中最核心的部分。
(3)天然支持 per-CPU / 多 fd 模型
一个很典型的模式是:
- 为每个 CPU 创建一个 perf fd
- 把同一个 BPF 程序附加到所有这些 fd 上
这在 program attach 模型下是顺理成章的事情:
1
2
3
4
| for_each_cpu(cpu) {
perf_fd = perf_event_open(..., cpu, ...);
link[cpu] = bpf_program__attach_perf_event(prog, perf_fd);
}
|
而 skeleton attach 并不擅长表达这种 “一对多、运行时生成”的 attach 关系。
(4)错误处理逻辑更清晰
手动管理 perf fd 和 link,也意味着:
- perf_event_open 失败时可以:
- 跳过某些 CPU
- 降级采样策略
- 做重试或 fallback
- attach 失败时可以单独处理,而不是整体失败
对比小结
需要强调的一点是,底层其实并没有“谁更高级”:
无论是 skeleton attach 还是 bpf_program__attach_perf_event,最终内核里做的事情本质上是一样的——建立 bpf_link,把程序绑定到事件上。
对当前的 perf 采样监控场景来说:
- 采样频率、CPU 绑定、fd 数量都是运行时决策
- 需要 per-CPU 创建 perf fd
- 需要清晰的错误处理和资源管理路径
因此在用户态创建 perf_event fd,并使用 bpf_program__attach_perf_event 逐个 attach,是更自然、也更可控的做法。
参考
- eBPF 入门实践教程十二:使用 eBPF 程序 profile 进行性能分析
- eBPF 性能分析实战 - eBPF 在性能分析中的应用
- Perf IPC 与 CPU 利用率 - perf 原理深入解析
- perf_event_open 手册页 - 官方文档参考
- FlameGraph 工具 - 火焰图生成工具
- blazesym 符号化库 - 高性能符号化库